
논문을 쓰기 위해 다시(?) 이해해보는 f1-score.
(결과를 돌려봤는데 이해가 안됨..ㅠㅠㅠㅠ)
전반적으로 아래 유튜브를 보며 이해했지만 중간중간 개인적으로 잘 와닿지 않는 부분들도 있어서 내가 보는 용도로
다시 정리해보기로 했다. Business Analytics 수업을 들으며 분명히 배웠는데 이게 막상 실제로 내가 필요해서 써먹으려고 보니 설렁설렁 이해하고 넘어간 것으로는 한계가 있다..ㅠ
[Confusion Matrix]
먼저 Confusion Matrix를 그리는 것부터 시작하는데,
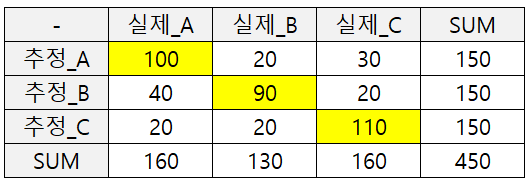
아래의 추정과 실제 각각의 경우의 수를 기록한 표를 Confusion Matrix라고 한다.

[Accuracy]
그럼 기본으로 많이 사용되는 Accuracy로 시작해보자.
(SUM의 경우는 보통 표시 안하는 것 같은데 계산을 좀 편하게 해보려고 넣어놨다)
Accuracy는 전체 중에서 정답을 제대로 맞춘 비율을 말한다.
그러므로 노란 색으로 표시한 정답(100+90+110) / 전체(450) = 300/450 = 0.875
단, Accuracy의 경우 각 구분자별로 데이터의 비율이 크게 차이가 없어야 의미가 있다.
아래는 영상보다 좀 더 부풀려서 표현해본 데이터이다.
이 경우에 Accuracy는 정답(400+0+0) / 전체(450) = 0.888

위의 모델보다 Accuracy가 높지만, 실상은 A만 100% 맞추고 B와 C는 전혀 맞추지 못하고 있다.
그러므로 단순히 Accuracy가 높다고 좋은 모델이라고 하기엔 한계가 있으며, 데이터가 어떤 상태에 있는지에 대해 먼저 살펴보고 알맞은 모델을 적용해야 한다. 이 때 이를 고려하여 판단할 수 있는 기준 중 하나가 f1-score라고 보면 된다.
[f1-score]
f1-score는 아래와 같이 계산된다.
f1-score = 2 * (precision * recall) / (precision + recall)
즉, precision과 recall의 조화평균을 f1-score라고 부르고 있다.
이를 계산하려면 precision(=정확도, 정밀도)과 recall(=검출율, 재현율)에 대해 이해가 필요하다.
(생각해보니 굳이 재현율이 얼마야?라고 묻지 않으므로 번역 자체가 필요가 없는 것 같기도..)
그리고 precision과 recall을 계산하려면 다시 또 타고 들어가서 아래의 개념이 필요하다.
(neverending story..)

TP(=True Positive) : True로 추정했는데 실제도 True인 것.
FP(=False Positive) : True로 추정했지만 실제는 False인 것.
FN(=False Negative) : False로 추정했지만 실제는 True인 것.
TN(=True Negative) : False로 추정했는데 실제도 False인 것.
일단 T로 시작하면 맞춘 것, F로 시작하면 틀렸다고 구분할 수 있으며,
P면 True로 추정했다, N이면 False로 추정했다고 구분된다.
다시 돌아와서 precision과 recall을 살펴보자.
precision = TP / (TP+FP)
TP+FP, 즉 맞았건 틀렸건 True라고 추정한 값들 중에서 True를 맞춘 비율이라고 볼 수 있다.
표를 기준으로 하면 아래처럼 빨간 테두리를 전체(분모)로 그 중에 노란 음영처리한 TP의 비율이다.

recall = TP / (TP+FN)
TP+FN, 추정을 뭘로 했건 실제 True인 값들 중에서 True를 맞춘 비율이라고 볼 수 있다.
표를 기준으로 하면 아래처럼 빨간 테두리를 전체(분모)로 그 중에 노란 음영처리한 TP의 비율이다.

결국 precision이나 recall이나 분모가 달라질 뿐 결국은 TP를 얼마나 잘맞추는지에 관심이 있다.
다시 Confusion Matrix로 돌아와보자.
먼저 precision을 구하려면 TP와 FP가 필요하다.
A, B, C 각각의 경우에 따라 계산 해보면,
A의 경우, TP = 100, FP = 20 + 30 or 150 - 100 = 50
그러므로 precision(A) = 100 / 150 = 0.67
B의 경우, TP = 90, FP = 40 + 20 or 150 - 90 = 60
그러므로 precision(B) = 90 / 150 = 0.60
C의 경우, TP = 110, FP = 20 + 20 or 150 - 110 = 40
그러므로 precision(C) = 110 / 150 = 0.73
precision의 평균을 구해보면 (precision(A) + precision(B) + precision(C)) / 3 = 0.67
다음으로 recall을 구하려면 TP와 FN이 필요하다.
다시 A, B, C 각각의 경우에 따라 계산 해보면,
A의 경우, TP = 100, FN = 60
그러므로 recall(A) = 100 / 160 = 0.63
B의 경우, TP = 90, FN = 40
그러므로 recall(B) = 90 / 130 = 0.69
C의 경우, TP = 110, FN = 50
그러므로 recall(C) = 110 / 160 = 0.69
recall의 평균을 구해보면 (recall(A) + recall(B) + recall(C)) / 3 = 0.67
이를 바탕으로 f1-score를 구해보면 아무튼 평균이므로 둘의 조화평균을 구해보니 0.67이 나온다.
f1-score = 2 * 0.67 * 0.67 / (0.67 + 0.67) = 0.67
결국 첫 번째 Confusion Matrix의 경우 Accuracy는 0.875, f1-score는 0.67이 나온다.
다음 Confusion Matrix로 가보자.
극단적으로 설계했으므로 나름 유의미하게 나오지 않을까?
우선 precision을 구해보자.
A의 경우, TP = 400, FP = 0. 그러므로 precison(A) = 1
B의 경우, TP = 0, FP = 30. 그러므로 precision(B) = 0
C의 경우, TP = 0, FP = 20. 그러므로 precision(C) = 0
precision의 평균을 구해보면 (1+0+0) / 3 = 0.33
다음으로 recall을 구해보자.
A의 경우, TP = 400, FN = 30. 그러므로 recall(A) = 400 / 430 = 0.93
B의 경우, TP = 0, FN = 10. 그러므로 recall(B) = 0
C의 경우, TP = 0, FN = 10. 그러므로 recall(C) = 0
그러므로 recall의 평균을 구해보면 (0.93 + 0 + 0) / 3 = 0.31
동일하게 f1-score를 구해보면 0.32가 나옴을 확인할 수 있다.
결국 두 번째 Confusion Matrix의 경우 Accuracy는 0.888, f1-score는 0.32가 나온다.
결국 Acc, f1-score의 조합을 보면 Confusion Matrix별로 첫 번째는 (0.875, 0.67) 두 번째는 (0.888, 0.32)
Accuracy로 봤을 때 두 번째가 높았지만, f1-score를 추가로 고려해줌으로써 첫 번째 경우가 데이터에 적합한 모델이
잘 적용된 케이스임을 확인할 수 있었다.
F1-score의 경우 Precision과 Recall이라는 개념을 도입함으로써 각 경우별로 찢어서 확률을 계산해주다보니, 실제건 추정이건 모수가 적은 케이스가 있어도 이에 대한 보정치가 들어가면서 어느 하나의 케이스에 대한 성능이 확 떨어진다면 이에 대해 Accuracy에 비해 훨씬 가중치가 들어간다고 이해할 수 있을 것 같다.
영상과는 실제와 추정의 축이 다르게 표현되어 있어서 가로세로가 다름에 유의해주시길.
[머신러닝] 다중 분류 모델 성능 측정 (accuracy, f1 score, precision, recall on multiclass classification) - YouTube
'대학원 라이프 > Step2.1 : 데이터공부' 카테고리의 다른 글
| 데이터공부#3 대시보드(dashboard)란 무엇인가? (0) | 2022.11.18 |
|---|---|
| 데이터공부#2 에이전트(Agent)란 무엇인가? (0) | 2022.09.13 |
| 데이터공부#1 데이터과학, 인공지능, 머신러닝, 딥러닝 용어 구분 (1) | 2022.09.10 |



댓글